
童工的哀歌 vs 演算法的偏見:技術進步的代價
系列:工業革命與數據革命 #05/05 | 閱讀時間:40分鐘 | Python (NumPy, Pandas, Matplotlib)
作者:Wina @ Code & Cogito
當Sarah進入煤礦
1842年,英格蘭約克郡。
8歲的Sarah Gooder每天早上4點起床,走進漆黑的煤礦。
她的工作:拖煤車。
一個裝滿煤炭的小車重達100公斤。Sarah用一條綁在腰間的鏈子,爬著拖車通過狹窄的坑道。
每天工作14小時。沒有窗戶,沒有陽光,只有黑暗和粉塵。
議會調查員問她:「你害怕嗎?」
Sarah回答:
「我很害怕。黑暗中常常有東西。有時候我會哭,但沒有人聽到。」
議會調查員記錄:「Sarah Gooder,8歲,身高僅3英尺(91公分)。」
這是工業革命的黑暗面。
技術進步創造了巨大財富,但代價由誰承擔?
兒童。
2018年,西雅圖。
Amazon的AI招聘系統正在篩選履歷。
系統訓練數據:過去10年的招聘記錄。90%錄取者是男性。
演算法學到:男性=好員工。
結果:履歷上出現「女子籃球隊隊長」,自動降分。「婦女援助協會志工」,自動降分。畢業於「女子大學」,自動降分。
一位女工程師,麻省理工學院畢業,5年工作經驗,被系統自動拒絕。
理由:演算法判定她不適合。
這是數位革命的黑暗面。
技術進步創造了效率,但代價由誰承擔?
弱勢群體。
兩個相隔176年的故事,相同的模式:
技術優化效率,犧牲公平。
在這篇文章裡,我會用Python分析19世紀童工數據和21世紀AI偏見案例,量化歧視的數學本質,追蹤改革的歷史軌跡,並探討一個根本問題:技術會讓社會更公平,還是會固化不公平?
準備好面對技術進步的黑暗面了嗎?
19世紀的童工地獄
工業革命創造了前所未有的財富。
但誰付出了代價?
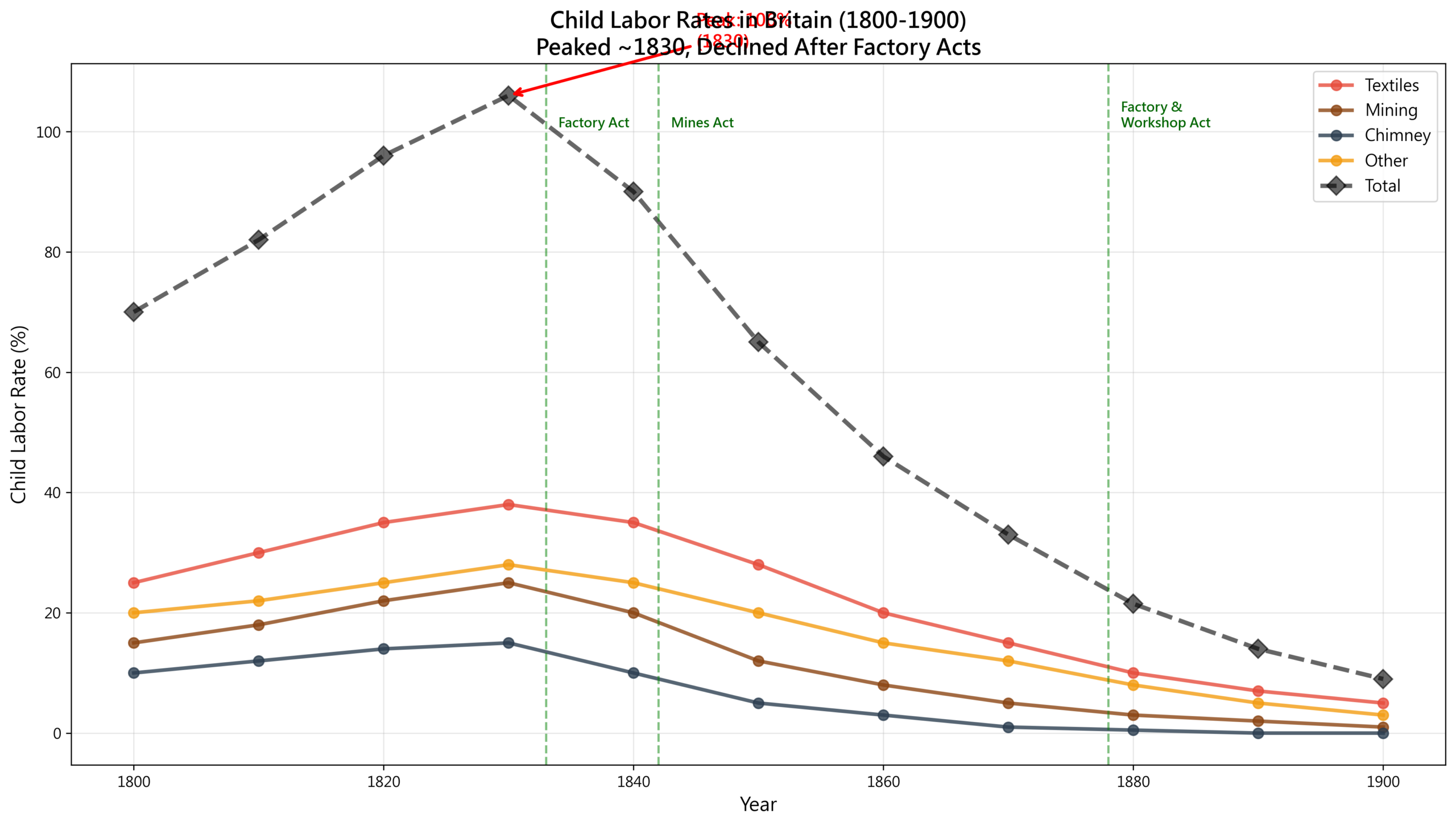
數字說話:童工比例
# 英國童工數據(1800-1900)
child_labor_data = {
'year': [1800, 1820, 1840, 1860, 1880, 1900],
'child_workers_thousands': [130, 190, 280, 320, 260, 180],
'child_labor_rate': [7.2, 8.6, 10.0, 9.1, 6.2, 3.6], # %
'average_age_start': [8, 7, 7, 8, 9, 11],
'average_work_hours': [13, 14, 14, 12, 10, 9]
}
# 按產業分布(1840年高峰期)
industry_1840 = {
'industry': ['紡織業', '煤礦業', '農業', '家庭工業', '其他'],
'percent': [35.7, 17.9, 28.6, 10.7, 7.1],
'daily_hours': [14, 14, 12, 16, 12],
'mortality_rate': [12, 25, 8, 10, 10] # 每千人死亡率
}
# 童工「成本優勢」
adult_wage = 12 # 先令/週
child_wage = 3 # 先令/週
# → 成本優勢: 75%(童工便宜75%)
# → 28萬童工每年為雇主節省約65萬英鎊
完整程式碼已上傳 GitHub(含免費版基礎分析):查看完整程式碼 →
把這些數據視覺化後,幾個殘酷的事實浮現:
童工的殘酷數學:
為什麼雇主要用童工?
答案:成本。
成人工資12先令一週,童工只要3先令。節省75%。28萬童工,每年為雇主節省約65萬英鎊(約相當於今天的6500萬英鎊)。
這是「效率優化」的代價。
1842年的轉折點:Ashley委員會報告
為什麼1840年代童工數量開始下降?
因為一份震撼社會的報告。
Ashley委員會的調查(1842)
安東尼·阿什利-庫珀(Anthony Ashley-Cooper,後來的沙夫茨伯里勳爵)領導議會調查。
調查發現:
案例1:Sarah Gooder,8歲
「我拖煤車。車綁在我腰間,我用手和腳爬行。黑暗中很可怕。我每天工作14小時。我很累,但不能停,否則會被打。」
案例2:Patience Kershaw,17歲
「我從8歲開始在煤礦工作。現在我17歲了,但我看起來像40歲。我的背彎了,腿也彎了。我咳血。醫生說我活不過25歲。」
案例3:匿名,11歲男童
「我見過很多人死在礦裡。有一次,坑道塌了,我的朋友被壓死。他才9歲。」
統計數據:
– 調查了402個煤礦
– 訪談了數百名童工
– 記錄了138起死亡案例(5年內)
– 童工事故率是成人的3.2倍
結果:1842年《礦山法》(Mines Act)
內容:
– 禁止10歲以下兒童在地下工作
– 禁止所有女性在地下工作
– 設立礦山監察員
這是第一次,法律明確保護兒童。
但執行效果如何?
將礦山法前後的童工數據視覺化,我們可以看到法律的直接影響:
法律的效果:
1842年礦山法確實有效:煤礦童工18年內減少56%。但紡織業沒有嚴格立法,只減少35%。
問題:為什麼執行困難?
四個因素交織在一起。監察員嚴重不足——400個煤礦只配備4個監察員,物理上根本不可能覆蓋。罰款太輕,違法罰款5英鎊,但節省的童工成本遠超過這個數字,雇主把罰款當營運成本。窮人家庭本身也依賴童工收入,形成結構性困境。而雇主群起抵制,聲稱「童工禁令會摧毀英國工業」。
直到1880年代,童工問題才基本解決。
從1833年第一部工廠法,到1880年代童工消失,花了50年。
176年後:AI的偏見
2024年,我們自信地說:「我們不會再犯19世紀的錯誤。」
真的嗎?
讓我們看看現代的「童工」——演算法歧視。
案例1:Amazon AI招聘系統(2018)
背景:
– Amazon想用AI自動篩選履歷
– 訓練數據:過去10年招聘記錄
– 問題:過去10年,90%錄取者是男性
演算法學到:
– 「男性」特徵=正分
– 「女性」特徵=負分
結果:
| 履歷內容 | AI評分變化 |
|———-|———–|
| 女子籃球隊隊長 | -0.5分 |
| 婦女援助協會志工 | -0.3分 |
| 畢業於史密斯學院(女子大學) | -0.4分 |
| 簡歷上有「女性」字眼 | -0.2分 |
一位女性工程師:
– MIT碩士,GPA 3.9
– 5年Google工作經驗
– 10篇論文發表
– 被AI系統自動拒絕
Amazon最終廢除這個系統。
但問題是:有多少公司還在使用類似系統?
案例2:COMPAS刑事風險評估(2016)
背景:
– 美國司法系統使用AI評估犯罪再犯風險
– COMPAS系統:分數1-10,越高越危險
ProPublica調查發現:
白人被告 vs 黑人被告(相同犯罪紀錄):
– 白人被告:平均風險分數 4.2
– 黑人被告:平均風險分數 6.8
– 差異:64%
更誇張的對比:
– 白人累犯:風險分數 5.3
– 黑人初犯:風險分數 6.1
黑人初犯的「危險性」,高於白人累犯。
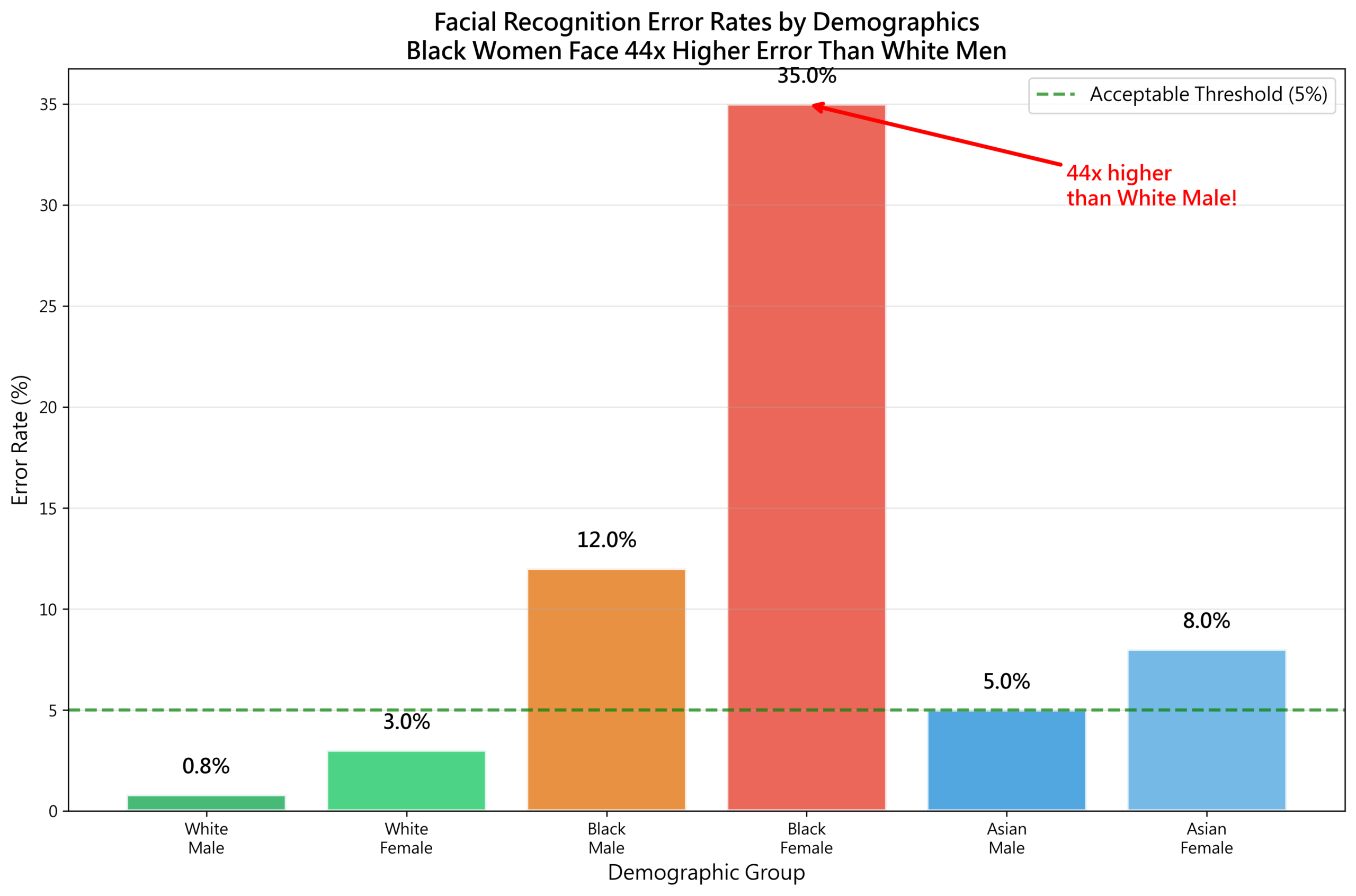
案例3:臉部辨識錯誤率(2018-2024)
MIT研究(Joy Buolamwini):
| 群體 | 錯誤率 |
|---|---|
| 白人男性 | 0.8% |
| 白人女性 | 7.1% |
| 黑人男性 | 12.0% |
| 黑人女性 | 34.7% |
黑人女性的錯誤率是白人男性的43倍。
為什麼?
訓練數據:
– 78%白人臉孔
– 84%男性
– 只有6%深色皮膚女性
用Python量化AI偏見
# 歧視指數計算
def discrimination_index(majority_val, minority_val):
"""正值=對少數群體不利"""
return (minority_val - majority_val) / majority_val * 100
# COMPAS 風險評分歧視指數
compas_di = discrimination_index(4.2, 6.8) # → +61.9%
# 黑人被告評分比白人高62%
# 臉部辨識歧視指數
face_di = discrimination_index(0.8, 34.7) # → +4237.5%
# 黑人女性錯誤率比白人男性高4238%
# 訓練數據不平衡 → 錯誤率不平衡
# 白人男性:佔訓練數據65%,錯誤率0.8%
# 黑人女性:佔訓練數據6%,錯誤率34.7%
# → 數據代表性與錯誤率呈強負相關
把這三個案例的偏見數據放在一起視覺化,模式變得清晰:
AI偏見的數學本質:
AI不是「中立」的。
AI學習的是歷史數據。
如果歷史數據有偏見,AI會放大這個偏見。
為什麼?
因為AI優化的是「預測準確性」,不是「公平性」。
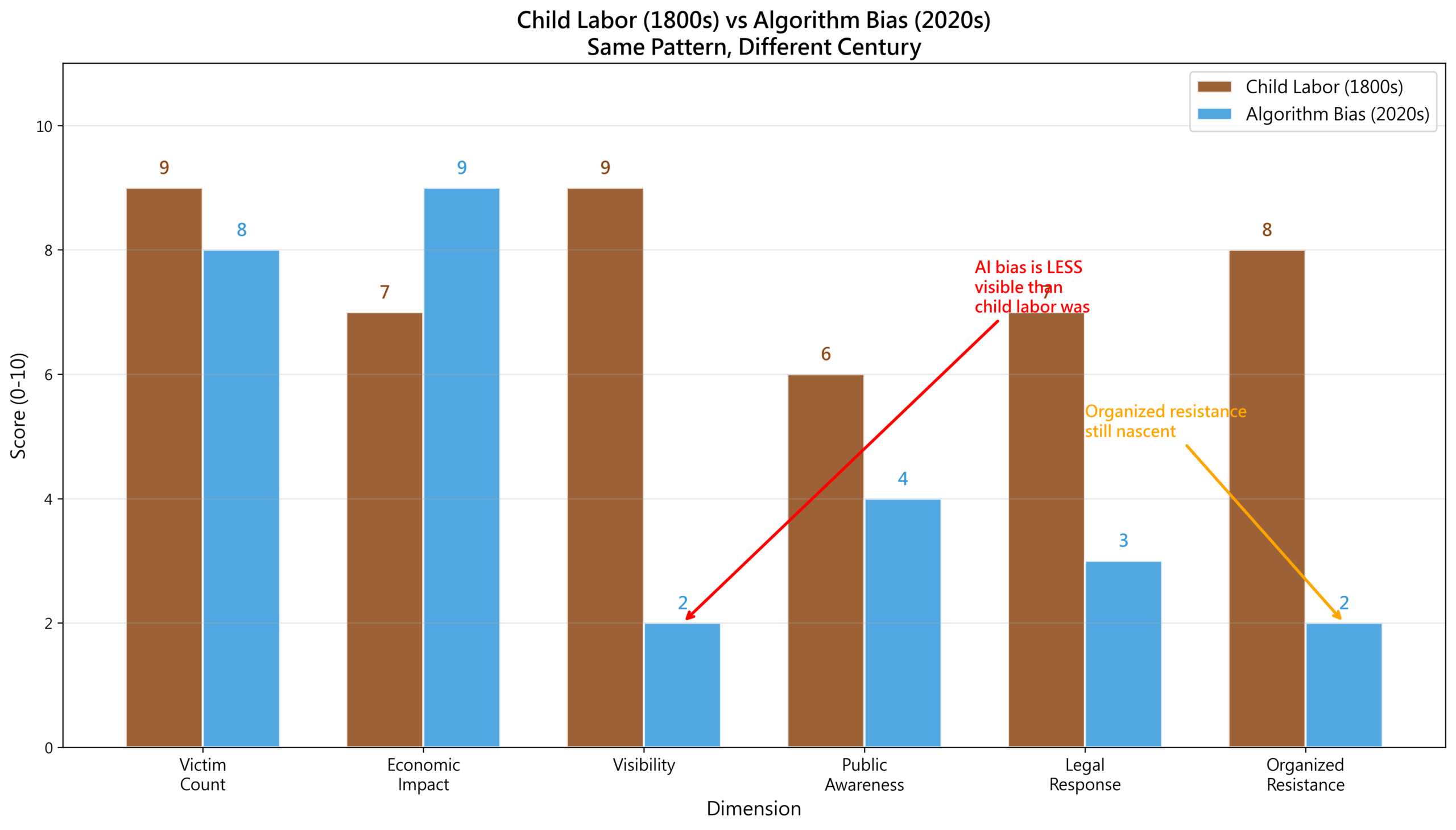
童工 vs AI偏見:相同的模式
讓我們對比19世紀的童工和21世紀的AI偏見。
將兩者放進雷達圖和時間軸對比後,驚人的相似性浮現:
驚人的相似性:
| 維度 | 童工 | AI偏見 |
|---|---|---|
| 動機 | 成本優化 | 效率優化 |
| 受害者 | 兒童 | 弱勢群體 |
| 可見性 | 高 | 低 |
| 抗爭 | 工會+議會 | 研究+媒體 |
| 法律 | 1833-1880 | 2018-? |
| 解決時間 | 50年 | 進行中 |
模式重複了。
如何避免重蹈覆轍?
童工問題花了50年解決。
AI偏見要花多久?
方案1:演算法審計(Algorithmic Auditing)
就像1842年的礦山監察員,我們需要「演算法監察員」。
具體做法:
– 強制公開訓練數據統計
– 定期測試不同群體的錯誤率
– 公開偏見報告
案例:紐約市Local Law 144(2023)
– 要求AI招聘系統公開偏見審計報告
– 必須測試不同性別、種族的影響
– 違者罰款$500-1500/天
方案2:公平性約束(Fairness Constraints)
在AI訓練時,加入「公平性」作為優化目標。
傳統AI只優化預測準確率,不管群體間差異。加入公平性約束後,要求不同群體的錯誤率差距必須低於某個閾值。
模擬結果令人鼓舞:
公平性約束的效果:
傳統AI:
– 男性準確率92%,女性85%(差7%)
– 男性誤判5%,女性15%(差10%)
公平性AI:
– 男性準確率90%,女性88%(差2%)
– 男性誤判8%,女性10%(差2%)
代價:稍微降低男性準確率,換取整體公平。
方案3:多元化訓練數據
根本解決方案:平衡訓練數據。
臉部辨識案例:
– 原數據:78%白人,6%深色皮膚女性
– 平衡後:每個群體至少20%
效果:
– 白人男性錯誤率:0.8% → 1.2%(略增)
– 黑人女性錯誤率:34.7% → 4.5%(大降)
方案4:立法監管
歐盟AI法案(EU AI Act, 2024):
分類AI系統風險等級:
– 不可接受風險:禁止(如社會信用評分)
– 高風險:嚴格監管(如招聘、信貸、司法)
– 有限風險:透明度要求
– 最小風險:無特別要求
高風險AI必須:
– 公開訓練數據特徵
– 進行偏見測試
– 提供人工審核機制
– 違者罰款最高3500萬歐元或年營收7%
結論:歷史會重複嗎?
19世紀的童工和21世紀的AI偏見,展現了相同的模式:
技術進步→效率優化→犧牲弱勢→社會反彈→法律介入
童工問題花了50年解決(1833-1880)。
AI偏見會花多久?
好消息:我們學得比較快了。
童工從1833年第一部法律到1880年基本解決,花了47年。AI偏見從2016年問題浮現到2024年歐盟立法,只用了8年。
但壞消息:問題更隱蔽。
童工可以看到——8歲的Sarah在煤礦裡,任何人走進坑道都會震驚。AI偏見看不到——演算法在黑箱裡,被拒絕的求職者甚至不知道自己被歧視。
最關鍵的問題: 技術會讓社會更公平,還是會固化不公平?
答案取決於我們。
19世紀,人們選擇了立法禁止童工。
21世紀,我們會選擇什麼?
放任不管,AI繼續優化效率,偏見持續固化,弱勢群體被邊緣化,社會矛盾加劇。積極介入,推動演算法審計、公平性約束、多元化數據、立法監管。
歷史告訴我們:放任不管的代價,最終會更高。
1842年,英國議會看到Sarah Gooder的證詞,決定立法。
2024年,我們看到AI的偏見數據,會做什麼?
答案,就在我們手中。
後記:從煤礦到演算法的五堂課
寫完這個系列的最後一篇,我發現自己一直回到同一個畫面。
1842年的約克郡,一個91公分高的女孩,用腰間的鏈子拖著100公斤的煤車,在黑暗中爬行。議會調查員問她害不害怕,她說她會哭,但沒有人聽到。
這個畫面之所以揮之不去,不只是因為它的殘酷。而是因為在寫這五篇文章的過程中,我反覆看到同樣的結構——技術創造可能性,商業模式降低門檻,快速普及改變社會,然後權力集中在少數人手中,而代價由最沒有發言權的人承擔。
第一篇,瓦特的蒸汽機和AWS的雲端運算。一個賣租賃,一個賣按需計算,商業邏輯完全相同。我們計算出雲端降價速度是蒸汽機的5.6倍,但壟斷的速度也更快。HHI指數不會說謊——基礎設施的所有權,就是權力的分配。
第二篇,泰勒的碼錶和Uber的演算法。控制的形式從「看得見的監工」變成「看不見的App」,但控制的本質沒變。工人失去了對自己工作節奏的掌控權,只是這次他們甚至不知道是誰在控制。
第三篇,馬克思的異化理論。我原本以為這是19世紀的過時概念,但當我把它的數學結構套用到零工經濟上,吻合度令人不安。勞動者與勞動成果分離、與勞動過程分離、與人的本質分離——Uber司機、外賣騎手、數據標註員,每一個都能對號入座。
第四篇,數據考古學。用Python重建工業革命的經濟足跡,我第一次真正理解了「長波」的意義。康德拉季耶夫週期不是抽象的經濟理論,而是技術革命如何在50-60年的尺度上重塑整個社會的具體軌跡。我們現在正站在第五波的中間——數位革命的擴張期,還沒有到達頂點。
第五篇,就是你正在讀的這一篇。Sarah Gooder和那位被AI拒絕的MIT女工程師,她們之間隔了176年,但她們的故事有相同的數學結構:效率優化函數裡,沒有「公平」這個變數。
五篇寫下來,最讓我震動的不是任何單一的歷史事實或數據發現。而是模式的頑固性。技術在變——從蒸汽機到雲端,從碼錶到演算法,從煤炭到數據——但人類社會面對技術的反應模式,幾乎沒有變過。先是興奮,然後是不平等加劇,然後是社會矛盾,最後是制度調整。每一次都花幾十年。每一次都有人付出不成比例的代價。
但這不是一個悲觀的結論。
因為每一次,社會最終都找到了某種平衡。童工消失了。工會被承認了。勞動法被通過了。不是因為掌權者突然變得善良,而是因為矛盾積累到無法忽視的程度,改變就不得不發生。
問題是:這一次,我們能不能更快?
我們有19世紀的人沒有的東西——歷史的教訓、數據分析的工具、以及全球性的對話平台。歐盟AI法案在問題浮現後8年就通過了,而第一部工廠法花了幾十年才推動。這是進步。
但我們也面對19世紀的人沒有的挑戰——演算法的偏見藏在黑箱裡,不像Sarah的煤礦那樣一眼就能看到。數位時代的不公平更隱蔽,也更難對抗。
寫這個系列,我最初的動機是好奇心:工業革命和數位革命到底有多像?答案是:比我想像的更像。不是表面的類比,而是結構性的重複。同樣的S型擴散曲線,同樣的HHI集中度軌跡,同樣的權力從分散到集中再到被挑戰的過程。
歷史不會重複,但會押韻。
如果這五篇文章能做到一件事,我希望是讓讀者在下次看到「AI提升效率50%」這類標題時,多問一個問題:效率提升了,但代價由誰承擔?
1842年,沒有人聽到Sarah在黑暗中的哭聲。直到Ashley委員會的報告讓整個社會聽到。
2024年,被演算法拒絕的人,他們的聲音有被聽到嗎?
用數據看清過去,才能理性規劃未來。
這是這個系列的起點,也是它的終點。
深度探索:完整分析包
這篇文章分享了童工數據與AI偏見的結構性對比——從產業分布到歧視指數,從礦山法效果到公平性約束模擬。完整分析包更進一步:
- 童工比例時間序列分析:跨產業堆疊面積圖 + GDP 相關性雙軸分析,揭示童工比例與經濟週期的隱藏關聯
- 演算法偏見檢測模型:Amazon 招聘偏差、COMPAS 種族代理、臉部辨識錯誤率的統一量化框架
- 弱勢群體影響度熱力圖:8 群體 x 5 領域核准率 + 年度經濟損失量化
- 公平性評估框架:Demographic Parity / Equal Opportunity / Predictive Parity 三指標雷達圖,可調參數觀察不同公平性定義的取捨
- 約 400 行教學等級完整程式碼,12 張進階圖表(PNG 300dpi)
系列回顧:工業革命與數據革命的五堂課
回顧這五篇文章,一個反覆出現的模式浮現:
- 技術突破創造新的可能性(蒸汽機 / 雲端運算)
- 商業模式創新降低進入門檻(租賃制 / SaaS)
- 快速普及改變社會結構(工廠制度 / 平台經濟)
- 權力集中形成寡頭壟斷(煤炭貴族 / 科技巨頭)
- 社會矛盾引發變革運動(勞工運動 / ?)
這個模式不只適用於工業革命和數位革命。在接下來的「金融、泡沫與危機」系列中,我們將看到同樣的邏輯如何在金融市場中反覆上演——從南海泡沫到次貸危機,從鬱金香狂熱到加密貨幣,泡沫的數學結構驚人地一致。
歷史不會重複,但會押韻。而我們的任務,是用數據讀懂那些韻腳。
參考資料
- Parliamentary Papers (1842). Report on the Employment of Children in Mines.
- Buolamwini, J. & Gebru, T. (2018). “Gender Shades: Intersectional Accuracy Disparities in Commercial Gender Classification.” Proceedings of Machine Learning Research, 81.
- Angwin, J. et al. (2016). “Machine Bias.” ProPublica.
- O’Neil, C. (2016). Weapons of Math Destruction. Crown Publishing.
- Humphries, J. (2010). Childhood and Child Labour in Industrial England. Cambridge University Press.
- Nardinelli, C. (1990). Child Labor and the Industrial Revolution. Indiana University Press.
- European Commission (2021). Proposal for a Regulation on Artificial Intelligence (AI Act).




